【cs231n】损失函数和梯度下降优化
损失函数
如何确定W,如何利用训练数据得到好的W。
损失函数:定义一个函数,输入W,然后定量计算W的好坏。
支持向量机SVM
给定一个样本$(xi,y_i)$,其中$x_i$是图片,$y_i$是图片真实对应的标签,就是第几类,i代表是训练集第i个样本。用支持向量机表示为:$$L_i = \sum{j\neq yi}max(0,s_j-s{y_i}+1)$$,S为这张图片通过分类器计算出来的各个类的得分。
这个式子也表示了如果真实的类的分数比其他类的分数大于1以上,那么这一项的损失就为0。那么为什么要选择大于1呢?其实1是可以任意确定的一个常数,我们并不关心损失函数中的分数的绝对值,而是关心分数的绝对差值,保证分类正确的分数要远远大于分类不正确的分数。因此这个常数项1就不是很重要,如果把W进行放大和缩小,那么每个分数也会放大和缩小,这个常数会消失。
例子:

分别计算每个样本的损失值,求平均数。 这个值就反映了当前我们的分类器在数据集上的分类效果。
- 如果汽车的分类分数变化了一丢丢,那么损失函数的值会变化吗?
- 不会,如果汽车的分数仍然比其他的类别的分数都大于1,那么损失函数的值还是0
- 损失函数的最大值和最小值是多少?
- 最小值为0,即所有样本的正确类别的分数都比其他类别的分数要大很多,最大值可能一个无穷大。
- 如果初始的W很小均匀分布,所有的S都为0,那么一个样本的损失函数值是多少?
- 答案为分类的个数-1,因为正确的类别为0,其他n-1个不正确的类别值为1
- 如果我们计算损失的时候,将正确的类别也加上了(即加上了j=$y_i$的情况),那么损失函数如何变化?
- 结果多了1
- 如果计算样本的损失值时,不是求和而是求平均值呢?
- 不会变化
- 如果损失值上加上平方,分类会如何变化?
- 会变成另外一种损失函数,从线性的变成了非线性的了
代码:
1 | |
正则化
如果找到一个损失值为0的W,我们应该使用吗?
其实我们并关心函数在训练数据集上拟合的怎么样,我们更关心在测试数据集上的表现。如果告诉分类器你唯一的目标就是去拟合训练数据集,分类器去尽力拟合训练的数据,甚至达到很完美的地步,这其实是很糟糕的情况。因为此时如果加入一些新的数据进来,那么这个拟合曲线就很难拟合这些新的点。因此我们更加希望,分类器是那个绿色的线而非蓝色的完全拟合所有训练数据的线
添加正则项R(W),鼓励模型以某种方式选择更简单的W,这里的简约取决于任务的规模和模型的种类。体现了奥卡姆剃刀理论:如果你有多个可以解释你观察结果的假设,一般来讲,你应该选择最简约的,因为这样可以在未来将其用于解释新的观察结果。

使用超参数$\lambda$来平衡损失函数中的数据损失项和正则项。
正则化的主要目的就是减轻模型的复杂度,而不是去视图拟合数据。
常用的正则化函数
最常用的就是L2正则化 ,L2,$\sumk\sum_lW{k,l}^2$
多项逻辑斯蒂回归(softmax)
在SVM中,我们并没有过多的关注得分,只是想要真实的正确类别的分数要比不正确的分类得分要高才好。并没有解释这些分数的真实含义,在softmax中将对这些得分进行一些计算以便得到分数的概率分布。
公式为 ,其中i为第i个样本,$ y_i $表示正确的类别,S为各个类别的分数
流程:
- 将得分进行指数运算
- 进行归一化处理
- 计算正确类别的损失,我们使用log进行运算,log是单调函数,加上负号就和我们想要的意思一致

下面是几个问题
- softmax的最大值和最小值
- 最小值:0,最大值:无穷。正确类别的概率为1取最小值,概率为0取最大值。实际中不可能取到,因为只有分数为无穷时才有可能
- 比较SVM和softmax这两个函数,如果我将正确的分类的分数提高一点,那么会对函数的结果有什么影响
- 我们已经分析过,对于SVM没有影响。但是对于softmax是会改变结果的,因为softmax是将所有的分数进行一个概率分布,如果正确的分类的分数提高,那么他在概率分布中占比就更大。这两种函数的策略有些不同,SVM是要求正确的分类分数比不正确的大于一个边界值就可以了,就不去管他了,而softmax是试着不断去提高正确分类的概率质量,并把不正确的分值降低。实际中这两个函数的差异不会造成很大的影响。
优化
我们已经通过数据集利用线性分类器计算出得分,并根据得分和数据真实的分类利用损失函数计算出损失值,通常会增加正则化操作,试图在训练数据之间进行权衡。那么下一步就是如何优化W,如何使W损失最小化?
实践中,我们使用不同的迭代方法进行优化
最简单粗暴的想法可能就是随机搜索,就是盲搜,这是一个很烂的算法,这里不多介绍。
梯度下降
比如说我们在山顶,要以最快的速度下山,我们可以每一次都沿着最陡峭的方向走一步,这样一直走到山底。在数学中,我们可以用梯度这个概念来表示最陡的方向,梯度指向函数增加最快的方向,负梯度就是函数减小最快的方向。

对于多元的情况,这个时候我们需要求的东西扩展成每个方向的『偏导数』,然后把它们合在一块组成梯度向量。
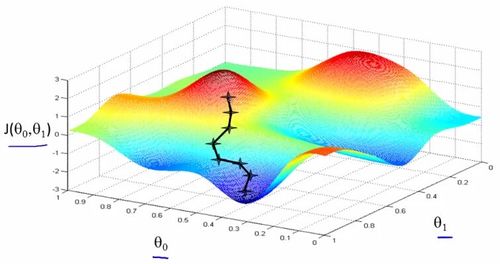
计算梯度
数值梯度
从定义上来算,也叫有限差分法,就是对于每一个维度在原始数值上加上一个很小的h,然后求出这个维度上的偏导,最后组合在一起得到梯度grad
1 | |
实际计算中,这个方法的问题很大。最突出的就是效率问题,比如在我们的CIFAR-10例子中,我们总共有30730个参数,因此我们单次迭代总共就需要计算30730次损失函数。这个问题在之后会提到的神经网络中更为严重,很可能两层神经元之间就有百万级别的参数权重,很低下
解析梯度

直接使用微积分的知识,写下梯度的表达式,这里梯度的表达式就是每个参数的偏导数,每次计算只需要带入公式即可。从W开始,计算dW或每一步的梯度。
实际中,我们不会直接使用数值梯度的方法,但是我们可以使用数值梯度的方法来验证解析梯度的准确性。
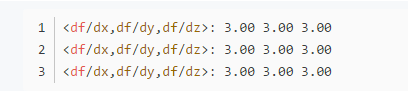
再举一个小例子(这里的反向传播法暂时不介绍):对于函数$f(x,y,z)=(x+y)z$
1 | |
梯度下降过程
在梯度下降算法中,首先我们初始化W为随机值,当为真时,我们计算损失和梯度,然后向着梯度相反的方向更新权重W值。
每次更新的步长是一个超参数,又叫学习率,就相当于每次选择最陡峭的方向走一步,这一步走多长。
其实在每次走一步时,会有很多种比较高级一点更新的法则,其本质就是梯度下降,每一步都试着朝着下坡走,这个后面详细讨论。
小批量随机下降
每次迭代时并不会去选择所有的数据集,这样的成本会很高,速度很慢。
随机梯度下降,每次迭代时,并不选择全部的样本,而是随机选择小部分的样本(minibatch),一般为2的次幂,利用小批量的数据来估计误差总和以及实际梯度